Последнее на форуме
Последние статьиСейчас на сайтеСейчас на сайте 0 пользователей и 0 гостей.
|
Ядро Linux за 10 минут (обзор)Немного историиОтносительно подробную историю создания ядра Linux можно найти в известной книге Линуса Торвальдса «Just for fun». Нас из неё интересуют следующие факты:
Эти факты в значительной мере определили пути развития ядра в дальнейшем, их следствия заметны и в современном ядре. В частности, известно, что Unix-системы в своё время разделились на два лагеря: потомки UNIX System V Release 4 (семейство SVR4) против потомков Berkley Software Distribution v4.2 (BSD4.2). Linux по большей части принадлежит к первому семейству, но заимствует некоторые существенные идеи из второго. Ядро в цифрах
Об архитектуре ядраВсе (или почти все) процессоры, которыми когда-либо интересовались производители Unix-подобных ОС, имеют аппаратную поддержку разделения привелегий. Один код может всё (в т.ч. общаться напрямую с оборудованием), другой — почти ничего. Традиционно говорят о «режиме ядра» (kernel land) и «режиме пользователя» (user land). Различные архитектуры ядер ОС различаются прежде всего подходом к ответу на вопрос: какие части кода ОС должны выполняться в kernel land, а какие — в user land? Дело в том, что у подавляющего большинства процессоров переключение между двумя режимами занимает существенное время. Выделяют следующие подходы:
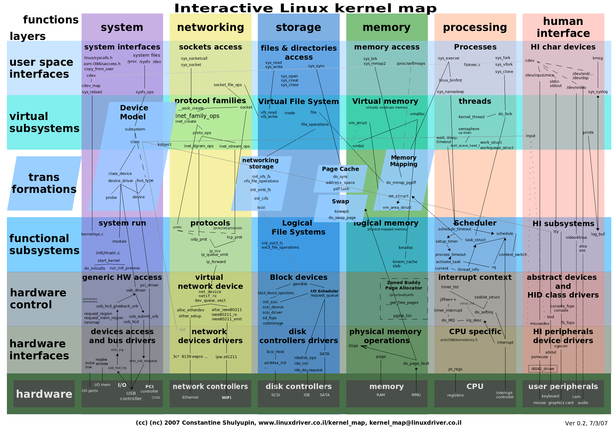
Ядро Linux начиналось как монолитное (глядя на существовавшие тогда Unix-ы). Современное Linux-ядро модульное. По сравнению с микроядром монолитное (или модульное) ядро обеспечивает существенно бо́льшую производительность, но предъявляет существенно более жёсткие требования к качеству кода различных компонентов. Так, в системе с микроядром «рухнувший» драйвер ФС будет перезапущен без ущерба для работы системы; рухнувший драйвер ФС в монолитном ядре — это Kernel panic и останов системы. Подсистемы ядра LinuxСуществует довольно широко известная диаграмма, изображающая основные подсистемы ядра Linux и их взаимодействие. Вот она: :
Собственно, в настоящий момент видно только, что частей много и их взаимосвязи очень сложные. Поэтому мы будем рассматривать упрощённую схему: :
Системные вызовыУровень системных вызовов — это наиболее близкая к прикладному программисту часть ядра Linux. Системные вызовы предоставляют интерфейс, используемый прикладными программами — это API ядра. Большинство системных вызовов Linux взяты из стандарта POSIX, однако есть и специфичные для Linux системные вызовы. Здесь стоит отметить некоторую разницу в подходе к проектированию API ядра в Unix-системах с одной стороны и в Windows[NT] и других идеологических потомках VMS с другой. Дизайнеры Unix предпочитают предоставить десять системных вызовов с одним параметром вместо одного системного вызова с двадцатью параметрами. Классический пример — создание процесса. В Windows функция для создания процесса — CreateProcess() — принимает 10 аргументов, из которых 5 — структуры. В противоположность этому, Unix-системы предоставляют два системных вызова (fork() и exec()), первый — вообще без параметров, второй — с тремя параметрами. Системные вызовы, в свою очередь, обращаются к функциям более низкоуровневых подсистем ядра. Управление памятьюЯдро Linux использует в качестве минимальной единицы памяти страницу. Размер страницы может зависеть от оборудования; на x86 это 4Кб. Для хранения информации о странице физической памяти (её физический адрес, принадлежность, режим использования и пр) используется специальная структура page размером в 40 байт. Ядро использует возможности современных процессоров для организации виртуальной памяти. Благодаря манипуляциям с каталогами страниц виртуальной памяти, каждый процесс получает адресное пространство размером в 4Гб (на 32х-разрядных архитектурах). Часть этого пространства доступна процессу только на чтение или исполнение: туда отображаются интерфейсы ядра. Существенно, что процесс, работающий в пространстве пользователя, в большинстве случаев «не знает», где находятся его данные: в ОЗУ или в файле подкачки. Процесс может попросить у системы выделить ему память именно в ОЗУ, но система не обязана удовлетворять такую просьбу. Управление процессамиЯдро Linux было многозадачным буквально с первого дня. К настоящему моменту оно имеет довольно хорошую поддержку вытесняющей многозадачности. В истории было известно два типа многозадачности:
Переключение процессов в linux может производиться по наступлению двух событий: аппаратного прерывания или прерывания от таймера. Частота прерываний таймера устанавливается при компиляции ядра в диапазоне от 100Гц до 1000Гц. Аппаратные прерывания возникают чуть ли не чаще: достаточно двинуть мышку или нажать кнопку на клавиатуре, да и внутренние устройства компьютера генерируют прерывания. Начиная с версии 2.6.23, появилась возможность собрать ядро, не использующее переключение процессов по таймеру. Это позволяет снизить энергопотребление в режиме простоя компьютера. Планировщик процессов использует довольно сложный алгоритм, основанный на расчёте приоритетов процессов. Среди процессов выделяются те, что требуют много процессорного времени и те, что тратят больше времени на ввод-вывод. На основе этой информации регулярно пересчитываются приоритеты процессов. Кроме того, используются задаваемые пользователем значения nice для отдельных процессов. Кроме многозадачности в режиме пользователя, ядро Linux использует многозадачность в режиме ядра: само ядро многопоточно. Традиционные ядра Unix-систем имели следующую… ну если не проблему, то особенность: само ядро не было вытесняемым. Пример: процесс /usr/bin/cat хочет открыть файл /media/cdrom/file.txt и использует для этого системный вызов open(). Управление передаётся ядру. Ядро обнаруживает, что файл расположен на CD-диске и начинает инициализацию привода (раскручивание диска и пр). Это занимает существенное время. Всё это время управление не передаётся пользовательским процессам, т.к. планировщик не активен в то время, когда выполняется код ядра. Все пользовательские процессы ждут завершения этого вызова open(). В противоположность этому, современное ядро Linux полностью вытесняемо. Планировщик отключается лишь на короткие промежутки времени, когда ядро никак нельзя прервать — например, на время инициализации некоторых устройств, которые требуют, чтобы определённые действия выполнялись с фиксированными задержками. В любое другое время поток ядра может быть вытеснен, и управление передано другому потоку ядра или пользовательскому процессу. Сетевая подсистемаСетевая подсистема ядра ОС, теоретически, почти вся может выполняться в пространстве пользователя: для таких операций, как формирование пакетов TCP/IP, никакие привелегии не нужны. Однако в современных ОС, тем более применяемых на высоконагруженных серверах, от всего сетевого стека — всей цепочки от формирования пакетов до работы непосредственно с сетевым адаптером — требуется максимальная производительность. Сетевой подсистеме, работающей в пространстве пользователя, пришлось бы постоянно обращаться к ядру для общения с сетевым оборудованием, а это повлекло бы весьма существенные накладные расходы. Сетевая подсистема Linux обеспечивает следующую функциональность:
В различных Unix-системах использовалось два различных прикладных интерфейса, обеспечивающих доступ к функциональности сетевой подсистемы: Transport Layer Interface (TLI) из SVR4 и sockets (сокеты) из BSD. Интерфейс TLI, с одной стороны, тесно завязан на подсистему STREAMS, отсутствующую в ядре Linux, а с другой — не совместим с интерфейсом сокетов. Поэтому в Linux используется интерфейс сокетов, взятый из семейства BSD. Файловая системаВиртуальная файловая система (VFS)С точки зрения приложений, в Unix-подобных ОС существует только одна файловая система. Она представляет собой дерево директорий, растущее из «корня». Приложениям, в большинстве случаев, не интересно, на каком носителе находятся данные файлов; они могут находиться на жёстком диске, оптическом диске, флеш-носителе или вообще на другом компьютере и другом континенте. Эта абстракция и реализующая её подсистема называется виртуальной файловой системой (VFS). Стоит заметить, что VFS в ядре Linux реализована с учётом идей из ООП. Например, ядро рассматривает набор структур inode, каждая из которых содержит (среди прочего):
Аналогично устроены структуры ядра, описывающие другие сущности ФС — суперблок, элемент каталога, файл. Драйверы ФСДрайверы ФС, как можно заметить из диаграммы, относятся к гораздо более высокому уровню, чем драйверы устройств. Это связано с тем, что драйверы ФС не общаются ни с какими устройствами. Драйвер файловой системы лишь реализует функции, предоставляемые им через интерфейс VFS. При этом данные пишутся и читаются в/из страницы памяти; какие из них и когда будут записаны на носитель — решает более низкий уровень. Тот факт, что драйверы ФС в Linux не общаются с оборудованием, позволил реализовать специальный драйвер FUSE, который делегирует функциональность драйвера ФС в модули, исполняемые в пространстве пользователя. Страничный кэшЭта подсистема ядра оперирует страницами виртуальной памяти, организованными в виде базисного дерева (radix tree). Когда происходит чтение данных с носителя, данные читаются в выделяемую в кэше страницу, и страница остаётся в кэше, а драйвер ФС читает из неё данные. Драйвер ФС пишет данные в страницы памяти, находящиеся в кэше. При этом эти страницы помечаются как «грязные» (dirty). Специальный поток ядра, pdflush, регулярно обходит кэш и формирует запросы на запись грязных страниц. Записанная на носитель грязная страница вновь помечается как чистая. Уровень блочного ввода-выводаЭта подсистема ядра оперирует очередями (queues), состоящими из структур bio. Каждая такая структура описывает одну операцию ввода-вывода (условно говоря, запрос вида «записать вот эти данные в блоки ##141-142 устройства /dev/hda1»). Для каждого процесса, осуществляющего ввод-вывод, формируется своя очередь. Из этого множества очередей создаётся одна очередь запросов к драйверу каждого устройства. Планировщик ввода-выводаЕсли выполнять запросы на дисковый ввод-вывод от приложений в том порядке, в котором они поступают, производительность системы в среднем будет очень низкой. Это связано с тем, что операция поиска нужного сектора на жёстком диске — очень медленная. Поэтому планировщик обрабатывает очереди запросов, выполняя две операции:
В современном ядре доступно несколько планировщиков: Anticipatory, Deadline, CFQ, noop. Существует версия ядра от Con Kolivas с ещё одним планировщиком — BFQ. Планировщики могут выбираться при компиляции ядра либо при его запуске. Отдельно следует остановиться на планировщике noop. Этот планировщик не выполняет ни сортировки, ни слияния запросов, а переправляет их драйверам устройств в порядке поступления. На системах с обычными жёсткими дисками этот планировщик покажет очень плохую производительность. Однако, сейчас становятся распространены системы, в которых вместо жёстких дисков используются флеш-носители. Для таких носителей время поиска сектора равно нулю, поэтому операции сортировки и слияния не нужны. В таких системах при использовании планировщика noop производительность не изменится, а потребление ресурсов несколько снизится. Обработка прерыванийПрактически все актуальные архитектуры оборудования используют для общения устройств с программным обеспечением концепцию прерываний. Выглядит это следующим образом. На процессоре выполняется какой-то процесс (не важно, поток ядра или пользовательский процесс). Происходит прерывание от устройства. Процессор отвлекается от текущих задач и переключает управление на адрес памяти, сопоставленный данному номеру прерывания в специальной таблице прерываний. По этому адресу находится обработчик прерывания. Обработчик выполняет какие-то действия в зависимости от того, что именно произошло с этим устройством, затем управление передаётся планировщику процессов, который, в свою очередь, решает, кому передать управление дальше. Тут существует определённая тонкость. Дело в том, что во время работы обработчика прерывания планировщик задач не активен. Это не удивительно: предполагается, что обработчик прерывания работает непосредственно с устройством, а устройство может требовать выполнения каких-то действий в жёстких временных рамках. Поэтому если обработчик прерывания будет работать долго, то все остальные процессы и потоки ядра будут ждать, а это обычно недопустимо. В ядре Linux в результате любого аппаратного прерывания управление передаётся в функцию do_IRQ(). Эта функция использует отдельную таблицу зарегистрированных в ядре обработчиков прерываний, чтобы определить, куда передавать управление дальше. Чтобы обеспечить минимальное время работы в контексте прерывания, в ядре Linux используется разделение обработчиков на верхние и нижние половины. Верхняя половина — это функция, которая регистрируется драйвером устройства в качестве обработчика определённого прерывания. Она выполняет только ту работу, которая безусловно должна быть выполнена немедленно. Затем она регистрирует другую функцию (свою нижнюю половину) и возвращает управление. Планировщик задач передаст управление зарегистрированной нижней половине, как только это будет возможно. При этом в большинстве случаев управление передаётся нижней половине сразу после завершения работы верхней половины. Но при этом нижняя половина работает как обычный поток ядра, и может быть прервана в любой момент, а потому она имеет право исполняться сколь угодно долго. В качестве примера можно рассмотреть обработчик прерывания от сетевой карты, сообщающего, что принят ethernet-пакет. Этот обработчик обязан сделать две вещи:
Соответственно, первое выполняет верхняя половина обработчика, а второе — нижняя. Драйвера устройствБольшинство драйверов устройств обычно компилируются в виде модулей ядра. Драйвер устройства получает запросы с двух сторон:
Version 1.0 Last updated 2010-03-05 20:25:06 YEKST
|
ОпросНужно ли делать основным новый сайт beta.lug-mgn.ru ? Да, нужно 83% Нет, не нужно 17% Сначала надо сделать на нём фичу X (указал в комментариях) 0% Сначала надо сделать для него дизайн (готов взяться) 0% Всего голосов: 6 |

 ))
))
1. s/Корпоративная многозадачность/Кооперативная многозадачность/
2. Цитата: "В современном ядре доступно несколько планировщиков: Anticipatory, Deadline, CFQ, noop. Существует версия ядра от Con Kolivas с ещё одним планировщиком — BFQ. Планировщики могут выбираться при компиляции ядра либо при его запуске."
В этом абзаце перепутаны планировщики процессов и IO-планировщики, а именно: IO-планировщик BFQ написал не Con Kolivas, он написал планировщик процессов BFS. IO-планировщик для устройства можно менять на лету в работающей системе.
Там же рядом можете посмотреть другую книгу "Инструменты Linux для Windows-программистов" - http://rus-linux.net/nlib.php?name=/MyLDP/BOOKS/Linux-tools/index.html , которая является фактически дополнением к "Модули ядра Linux".
P.S. А вот здесь: http://rus-linux.net/forum/viewtopic.php?f=3&t=1549 - форумное обсуждение книги "Модули ядра Linux", где можно получить любой уточняющий ответ на возникший вопрос, или оставить своё замечание, или указать на найденную ошибку.
А вот здесь, аналогично: http://rus-linux.net/forum/viewtopic.php?f=3&t=1495 - обсуждение "Инструменты Linux для Windows-программистов".